Lien entre les phonèmes
Explorer les séquences de phonèmes fréquents à l’aide de règles d'association
La fouille de données est une technique d'extraction de motifs, c’est-à-dire de récurrences intéressantes, utiles et parfois inattendues dans les bases de données afin de mieux comprendre les données et qui peuvent être utilisés pour prendre des décisions.
Et dans notre cas ?
Nous avons extrait des règles d'association (Agrawal 1993), qui permettent d'identifier des corrélations de sous-séquences phonétiques au sein des mots prononcés par des
enfants. Par exemple, une règle découverte dans les données pourrait indiquer qu'un enfant qui prononce fréquemment en milieu de mot le phonème « j » sera suivi du phonème « ɛ̃ » dans ce mot. Les règles d’association
sont extraites en fonction de deux critère : leur fréquence d'occurrence (dans notre cas supérieure à 100 occurrences) et la confiance dans l'évènement c’est-à-dire la proportion de mot contenant le premier
phonème qui contiennent aussi le deuxième. (supérieure à 0,8).
support
R. Agrawal; T. Imielinski; A. Swami: Mining Association Rules Between Sets of Items in Large Databases", SIGMOD Conference 1993: 207-216

Guide d'utilisation et de lecture de la visualisation Sankey:
Cette visualisation se décompose en 4 colonnes :
| col 1 | col 2 | col 3 | col 4 |
| Nom(s) enfant(s) | âges enfant(s) | sous-séquences phonétique 1 (seq1) | sous-séquences phonétique 2 (seq2) |
L'interprétation du Sankey s'effectue ainsi de gauche à droite en suivant les liens entre les colonnes, et permet de définir en fonction de l'âge quels phonèmes "seq1" entrainent d'autres phonèmes "seq2".
Une barre dans une colonne est d’autant plus grande qu’elle correspond à un nombre d’occurrence.
En ce qui concerne les filtres, il est possible de filtrer l'étude sur un enfant en particulier. Pour cela, il suffit de choisir son nom dans le premier filtre. Le deuxième filtre n'influence pas le contenu de l'étude mais son visuel. C'est une aide à la lecture qui permet de choisir la manière dont sont colorées les liens du diagramme de Sankey.
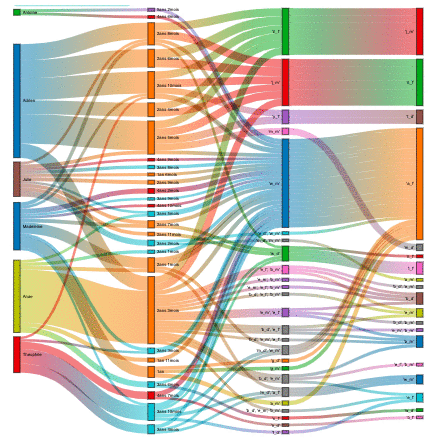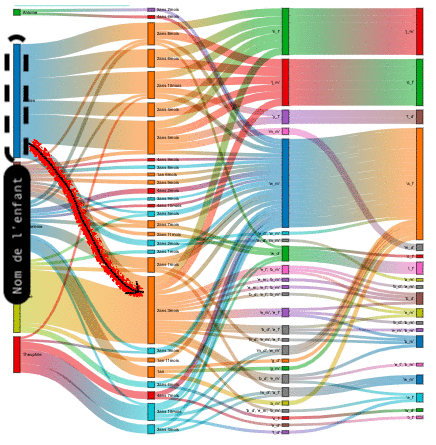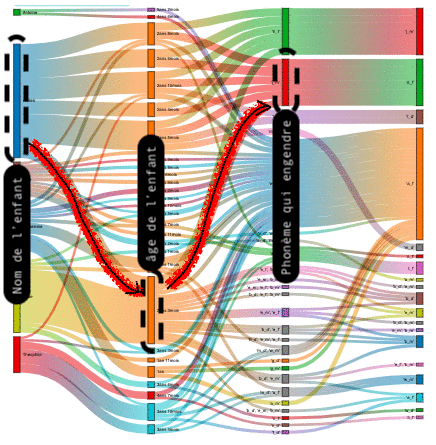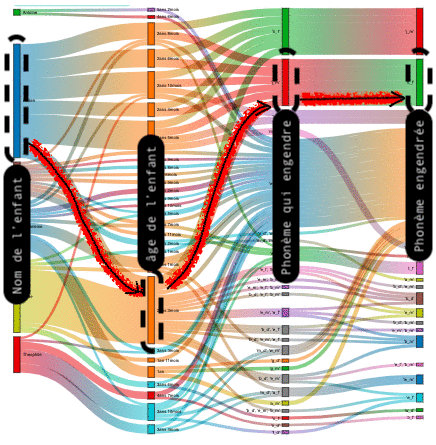
Phrase type de lecture : Dans plus de 80% des cas, lorsque "l 'enfant" a "tel âge", il prononce la sous-séquence phonétique "seq1" dans le même mot que la sous-séquence phonétique "seq2".
Cette étude a été réalisée avec l'aide de M. Alatrista-Salas et de la librairie pymining écrite par M. Infobart
Contacts: h.alatristas[at]up.edu.pe,
barthelemy[at]infobart.com